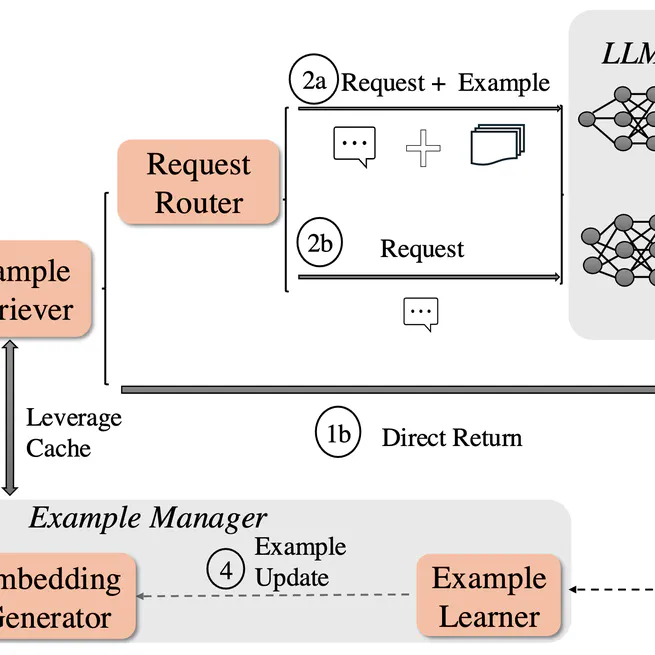
EchoLM: Accelerating LLM Serving with Real-time Knowledge Distillation
EchoLM is an in-context caching system that improves large language model (LLM) serving efficiency by leveraging semantically similar past requests as examples to guide response generation, resulting in significant throughput gains and latency reduction without compromising quality.
Jan 22, 2025